RomanAlfaz (رومن الفاظ) documentation
romanalfaz is a dictionary-based, predictive transliterator that converts roman-script Urdu words into their arabic-script equivalents. The tool automatically ranks and prioritizes matching suggestions based on their real-world usage frequency.
How it Works
The tool processes text using a specialized two-layer transformation workflow:
1. Intermediate Representation: It leverages the rule-based transliteration algorithm proposed by Tafseer Ahmed [1]. This converts the user’s roman-script Urdu input into an intermediate format designed to bridge the phonetic and structural spelling gaps between the two scripts.
2. Dictionary Lookup: The engine passes this intermediate form to SymSpellPy to execute an optimized dictionary search against a precompiled vocabulary list.
Baseline Vocabulary
The baseline included word list is built upon the CLE’s Urdu 5000 words dataset [2], which captures the most frequently used words in the Urdu language.
Core Workflow
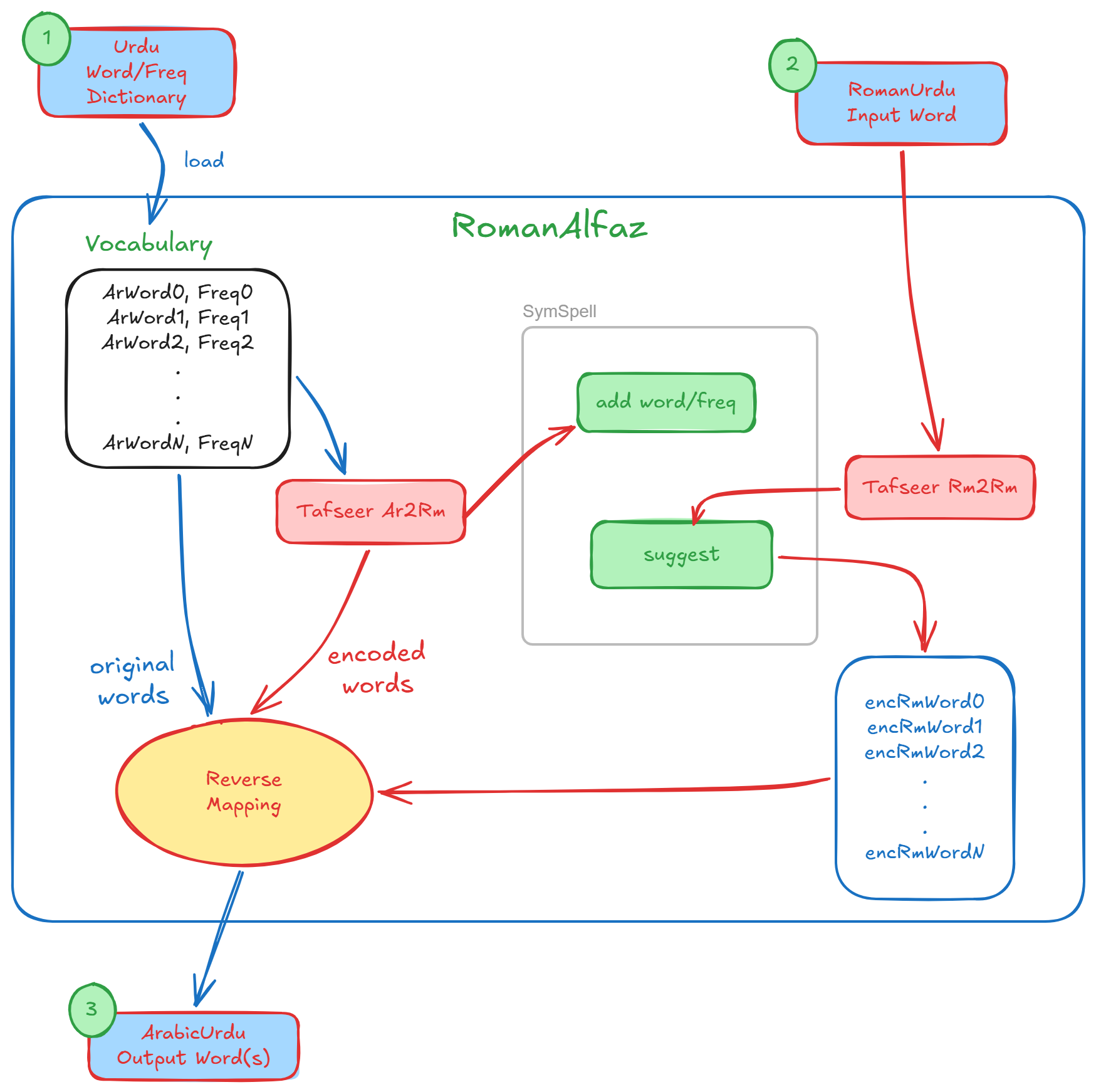
The internal workflow of the RomanAlfaz.
(1) Load a dictionary, (2) ask for suggestion(s) with a word in roman script, and (3) get the suggestions(s) in arabic script.
Blue arrows represent Arabic script and Red arrows represent Roman script.