RomanAlfaz Engine
This module contains the transliteration implementation logic for the romanalfaz package.
- romanalfaz.engine.getDefaultWordsFilename() str
Resolves the absolute path to the bundled ‘UrduWords5k.sym’ file.
- class romanalfaz.engine.Vocabulary(data: dict[str, int] | None = None)
Bases:
objectManages a collection of words with their frequencies and completion status.
- notifyChanges()
Triggers attached callbacks when internal state changes.
- add(word: str, count: int = 1)
Accumulate the count for a specific word.
If the word exists, its current count increases by count. Otherwise, it is added with the specified count.
- Parameters:
word (str) – The word to add or update.
count (int) – Number of times to increment the word’s frequency. Defaults to 1.
- remove(word: str)
Remove a word from both the counter and completed set if present.
- replace(oldWord: str, newWord: str)
Swap an existing word with a new one while preserving its frequency and status.
This is useful for correcting typos or updating terminology without losing data.
- Parameters:
oldWord (str) – The current word to be replaced.
newWord (str) – The replacement word.
- setCompleted(word: str, isCompleted: bool)
Toggle a word’s completion status.
- Parameters:
word (str) – The word to update.
isCompleted (bool) – True to mark as completed, False otherwise.
- save(filename: str, sep: str = '$')
Persist completed words and their frequencies to a file.
Writes only words that have been marked as completed, sorted by frequency (highest first).
- Parameters:
filename (str) – Path where the SymSpell-compatible file will be saved.
sep (str) – Separator character between word and count (default is ‘$’).
- classmethod load(filename: str, sep: str = '$') Vocabulary
Reconstruct a Vocabulary instance from a saved SymSpell file.
- Parameters:
filename (str) – Path to the source file.
sep (str) – Separator character used in the file (default is ‘$’).
- Returns:
A new Vocabulary object populated with loaded data.
- Return type:
- class romanalfaz.engine.Suggestion(arabic: str, encodedRoman: str, frequency: int)
Bases:
NamedTupleUrdu transliteration suggestion pairing Arabic script to encoded Roman.
- arabic: str
The original word in Arabic script.
- Type:
(str)
- encodedRoman: str
The intermediate encoded Roman representation.
- Type:
(str)
- frequency: int
The usage count of this specific word.
- Type:
(int)
- class romanalfaz.engine.RomanAlfaz(vocabularies: list[Vocabulary] | None = None)
Bases:
objectRomanAlfaz facilitates fuzzy matching between input roman-script Urdu transliteration and arabic-script Urdu words.It aggregates data from multiple source ‘Vocabulary’ instances at runtime, resolving cross-dictionary collisions by summing word frequencies.
Using the Observer Pattern, it automatically listens for mutations (additions, removals, modifications) within any registered Vocabulary and dynamically recompiles its internal lookup indices to guarantee a live, accurate system state.
- symSpell
The underlying SymSpell engine instance used to perform efficient, high-performance edit-distance lookups and spelling corrections.
- Type:
SymSpell
- reverseMapping
A lookup table mapping encoded Roman words to a set of their original native script Arabic variants along with their aggregate frequencies. Used to resolve homonyms during queries.
- Type:
defaultdict[str, set[tuple[str, int]]]
- vocabularies
A collection holding references to all currently attached and monitored Vocabulary instances active in the system.
- Type:
list[Vocabulary]
- addVocabulary(vocab: Vocabulary) None
Registers a new Vocabulary instance to be tracked by RomanAlfaz.
This method attaches the RomanAlfaz compilation manager as a listener to the target vocabulary. Any future mutations to that vocabulary will automatically trigger a lookup engine rebuild.
- Parameters:
vocab (Vocabulary) – The vocabulary instance to start monitoring.
- removeVocabulary(vocab: Vocabulary) None
Unregisters a monitored Vocabulary instance from RomanAlfaz.
This method detaches the callback listener, stops tracking the object, and strips its entries out of the active runtime search engine.
- Parameters:
vocab (Vocabulary) – The vocabulary instance to stop monitoring.
- recompileLookup() None
Recompiles the unified lookup indices from all attached Vocabularies.
This method acts as a central data processor. It resets the internal engines, flattens all attached source vocabularies, resolves multi-source word collisions by summing their frequencies, and fully rebuilds both the SymSpell fuzzy-search index and the Arabic reverse mapping.
- Complexity:
O(N) where N is the total number of unique words across all tracked Vocabulary instances.
- dictLookup(encRomanWord: str, *, distance: int) tuple[list[SuggestItem], list[SuggestItem], list[SuggestItem]]
Performs a fuzzy lookup in the dictionary based on edit distance.
This method queries SymSpell for words similar to the provided roman-script input and separates results by their exact match (distance 0) or edit distance (1 or 2).
- Parameters:
encRomanWord (str) – The Roman-script word to search for.
distance (int) – Maximum allowed edit distance (must be 0, 1, or 2).
- Returns:
A tuple containing three lists corresponding to exact matches (index 0), one-edit-distance matches (index 1), and two- edit-distance matches (index 2). Empty lists are returned if no matches exist for a specific distance tier.
- Return type:
tuple[list, list, list]
- Raises:
AssertionError – If the provided distance is outside the valid range [0, 2].
- suggest(romanWord: str, distance: int = 1, maxPredictions: int | None = 5) tuple[list[Suggestion], list[Suggestion], list[Suggestion]]
Generates a ranked list of suggested arabic-script Urdu words based on roman-script input. This method performs the fuzzy lookup and returns the encoded roman spellings, arabic-script representation and corresponding word usage frequencies for further processing.
- Parameters:
romanWord (str) – The roman-script word to transliterate.
distance (int) – Maximum edit distance to consider (default is 1).
maxPredictions (int) – Maximum number of unique suggestions per tier before truncating the list (default is 5). Use
Noneto get all suggestions.
- Returns:
A tuple containing three lists (in index order) exact matches, one-edit-distance matches, and two-edit-distance matches. Each list in turn is a list of
Suggestionitems sorted in decreasing order of frequency.- Return type:
tuple[list[Suggestion], list[Suggestion], list[Suggestion]]
- Raises:
AssertionError – If romanWord is not a string.
- getExactMatches(romanWord: str, maxPredictions: int | None = 5) list[Suggestion]
Generates of suggested arabic-script Urdu words which match exactly with the roman-script input.
- Parameters:
romanWord (str) – The roman-script word to transliterate.
maxPredictions (int) – Maximum number of unique suggestions to provide (default is 5). Use
Noneto get all suggestions.
- Returns:
A list of
Suggestionexact matching items in order of word frequency.- Return type:
list[Suggestion]
- Raises:
AssertionError – If romanWord is not a string.
- getBestMatch(romanWord: str) Suggestion | None
Get single best arabic-script Urdu word suggestion for the roman-script input.
- Parameters:
romanWord (str) – The roman-script word to transliterate.
- Returns:
Exact matching
Suggestionitem with the highest frequency.Noneis returned if no exact match is found.- Return type:
Suggestion | None
- Raises:
AssertionError – If romanWord is not a string.
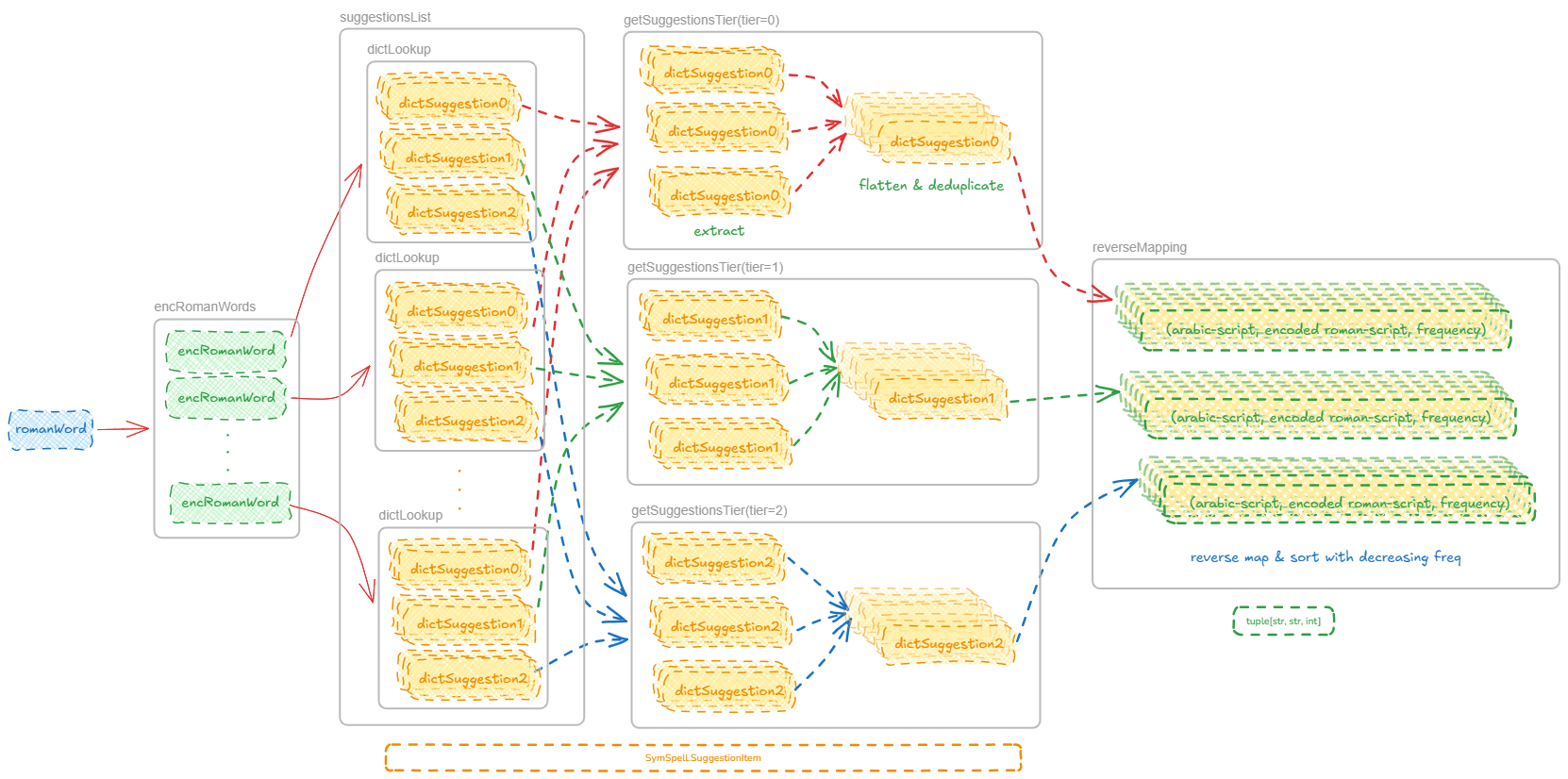
The internal workflow of the RomanAlfaz.suggest.
(1) Encode the roman-script input. (2) Get a suggestions list from SymSpell for each encoding of the roman-script word. (3) Separate the exact, one-edit and two-edit suggestions. (4) Flatten the three suggestions tiers into a single list each and remove duplicates. (5) Add arabic-script word using reverse mapping from the encoded roman word. (6) Sort with decreasing word usage frequency. (7) Return the three tiers.